


Sunday Rundown #79: All-Out "Shipmas" & Marshmallow Koala
Sunday Bonus #39: My workshop on image prompting and text in AI images.

Happy Sunday, friends!
Welcome back to the weekly look at generative AI that covers the following:
Sunday Rundown (free): this week’s AI news + a fun AI fail.
Sunday Bonus (paid): a goodie for my paid subscribers.
Let’s get to it.
Silly side note: My “Harry Potter in Soviet Russia” series was apparently one of the top 3 posts of 2024 in the r/Midjourney subreddit, according to their annual recap:
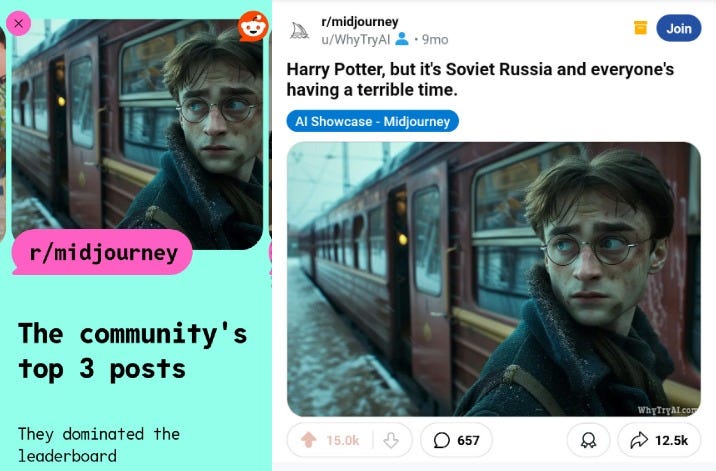
I previously wrote about this and other AI image experiments here:

🗞️ AI news
Here are this week’s many AI developments.
👩💻 AI releases
New stuff you can try right now:
Amazon released its own state-of-the-art Nova family, which includes a range of models that generate text, images, and video. (For Amazon Bedrock customers.)
Google has been busy:
The company is rolling out its long-awaited video model Veo to Vertex AI customers.
Vision-capable PaliGemma 2 model can “see” the world even better than its predecessor.
The latest iteration of Gemini—Gemini-Exp-1206—once again puts Google at #1 on the Chatbot Arena. (Try it on Google AI Studio.)
Pixel phones got lots of new Gemini-powered features and updates.
Hailuo AI released an impressive illustration-to-video upgrade I2V-01-Live. (Reminder: Hailuo was already “God Tier” in my recent video models test.)
Luma released its Luma Photon image model family that outperforms top dogs like FLUX 1.1 Pro and Midjourney V6.1. (Try it via Dream Machine or API.)
Meta open-sourced an upgraded LLama 3.3 70B that performs on par with Llama 3.1 405B but is much cheaper to run.
Microsoft is making Copilot Vision available to select Pro subscribers (via Copilot Labs). It sees your screen and works alongside you on your computer.
OpenAI is doing 12 days of
ChristmasOpenAI and so far came out with:Day 1: The full o1 reasoning model is finally out and can “see” images. Also, there’s a new $200/month ChatGPT Pro plan with unlimited o1 usage for serious researchers, heavy users, and crazy people.
Day 2: An expanded Reinforcement Fine-Tuning Research Program for developers and ML engineers. (So, not for most of us.)
Suno now has an Android app that lets you create and curate your music.
Tencent open-sourced an impressive Hunyuan Video model capable of creating high-quality, consistent videos:
🔬 AI research
Cool stuff you might get to try one day:
Google DeepMind showcased a model called Genie 2 that can turn a single input image into a playable, interactive world.
Hume previewed a Voice Control feature that lets you create precise custom voices by tweaking 10 voice attributes like assertiveness, enthusiasm, and more:
World Labs is also working on a world model that generates playable 3D worlds from a single image (similar to Genie 2).
📖 AI resources
Helpful AI tools and stuff that teaches you about AI:
“Democracies must maintain the lead in AI” - a conversation between FT’s Madhumita Murgia and Antrhopic’s CEO Dario Amodei.
“ChatGPT Pro Full Analysis (plus o1 paper highlights)” - another great deep dive by AI Explained.
“Moving generative AI into production” [PDF] - a paper by MIT Technology Review.
“OpenAI o1 System Card” [PDF] - pretty much what it says.
🔀 AI random
Other notable AI stories of the week:
Amazon and Anthropic have teamed up to build an AI supercomputer. (For contrast, I recently covered Denmark’s “Gefion” AI supercomputer, which follows a very different investment model.)
Google revealed an AI-driven weather forecasting model called GenCast that accurately predicts weather up to 15 days in advance.
OpenAI is expanding its roster of partners:
Anduril will incorporate OpenAI’s AI technologies into its defense systems.
A partnership with Future will bring specialist content from magazines like PC Gamer, TechRadar, and Tom’s Guide to ChatGPT.
🤦♂️ AI fail of the week
Silly koala. Marshmallows are for kids eating.

💰 Sunday Bonus #39: Watch my workshop on generating text inside AI images
I recently gave an online workshop that covered—among other things—the following:
Image prompting basics
How to get text into an image
Best image models for text generation
How to replace or add text to an existing image
Fixing near-perfect text using third-party tools
It went reasonably well…if the feedback is anything to go by:
“The workshop was fantastic! It was very well-organized and full of nice tips - I loved the Canva one!”
– Audience feedback
“Generally, I'm not a big fan of workshops because most of them are boring and not very useful. However, this workshop was really good, straight to the point, and full of great examples, especially thanks to Daniel's good teaching style. My English isn't perfect yet, but I understood the class!”
– Audience feedback
“It was fantastic. The Brazilian team here also liked it, they asked when is the next one.”
– Audience feedback
So if that sounds like your cup of tea, drink up:
Feedback time!
If there are other types of workshops, guides, or AI tool deep dives you’re especially interested in, please let me know. I’m always happy to hear from you.
Leave a comment below or shoot me an email at whytryai@substack.com.
You can also message me directly:
Thanks for putting this together really well done!
Congrats on the Midjourney silliness! I know conquering a subreddit isn't one of your life goals (is it?), but it's still really cool to see your stuff recognized as creative and innovative.
Credit to Google: when they decide to catch up, they really get into it. I've seen Gemini's frontier models improve dramatically over the last 3 months. I think you turned me onto a model that was way better, then like a day later they launched another one. I just switched over to this updated new hotness, 1206, and am looking forward to it.
GPT's o1 model is definitely powerful. I just noticed a cap on the number of questions you can ask per week. That caught my eye because I still haven't dived into the new business model there, but it makes sense that they want to sell this to crazy people. I'm just barely outside of that particular window, I think - sorry, Open AI!