
Just How Open Is "Open-Source" AI?
A nuanced look at the open-source vs. closed-source claims.

The release of DeepSeek-R1 put the closed-source vs. open-source discussion back on our radars.
DeepSeek got praise for open-sourcing its model while OpenAI protects its trade secrets like your grandma protects her blueberry pie recipe.

I, too, jumped on the bandwagon and called DeepSeek-R1 a “fully open-sourced reasoning model.”
But then I started coming across people arguing over whether DeepSeek’s models are truly open-source, open-weight, or something else.

If you enjoy drama and strongly worded opinions, there are many more Reddit threads on the topic.
At first, these discussions felt like nitpicky semantics to me, but I ended up getting curious about this distinction.
So I tried to educate myself.
I figured I’d find a nicely organized page with clear-cut definitions that tell me all I needed to know about open-source, open-weight, or open-anything-else.
I was wrong.
It turns out that, when it comes to AI, the open-source vs. closed-source distinction isn’t as neat as it might sound.
So come, take my hand, and let’s journey down this rabbit hole together.
AI models aren’t like traditional software
With old-school software, the distinction between closed source and open source is well-established.
Open Source Initiative (OSI) is a public-benefit nonprofit behind the current widely accepted definition of “open source” known as—wait for it—the Open Source Definition. It outlines ten criteria including access to the source code, free redistribution, and more.
This video does a decent job of covering the basics:
But AI models in general and LLMs in particular aren’t traditional software.
With large language models, we might be interested in e.g. their training data in addition to the final model weights when deciding if they’re “open-source.”
Right now, we’re in this awkward limbo where we apply outdated open-source definitions to LLMs while trying to align on a more appropriate set of criteria.
So what is “open-source” when it comes to AI?
That’s the thing: We don’t fully agree on this just yet.
As far as I can tell, there are two ongoing, partially overlapping efforts to define AI model openness. Notably, both are work-in-progress initiatives to arrive at a holistic picture but neither is a widely accepted industry standard at this time.
1. OSI’s “Open Source AI Definition”
Remember the Open Source Initiative, our friends from a few paragraphs ago?
In late 2024, OSI released version 1.0 of an AI-specific definition of “open source.” It’s called —you’ll never guess—”The Open Source AI Definition.”
Rather than focusing on the underlying components like training data and model weights, OSI chose to frame the definition in terms of whether an AI system as a whole can be freely used, studied, modified, and shared.
Here’s the relevant part:
An Open Source AI is an AI system made available under terms and in a way that grant the freedoms1 to:
Use the system for any purpose and without having to ask for permission.
Study how the system works and inspect its components.
Modify the system for any purpose, including to change its output.
Share the system for others to use with or without modifications, for any purpose.
If you’re into visuals, here:

The problem is that this broad-stroke definition is already leading to disagreements and fueling much of the Reddit drama. For instance, can a model be considered open-source under the above definition if its training data isn’t publicly available?
Perhaps the most prominent challenger of the new OSI definition is Meta, the self-proclaimed champion of open-source AI models.
Because Meta’s Llama family doesn’t fulfill OSI’s conditions for open-source AI,1 the company recently told The Verge:
“There is no single open source AI definition, and defining it is a challenge because previous open source definitions do not encompass the complexities of today’s rapidly advancing AI models.” - Faith Eischen, Meta spokesperson
For their part, OSI released an accompanying FAQ that addresses some of the pushback and unresolved questions while calling out specific models from Meta, xAI, Microsoft, and Mistral for not being compliant.
OSI continues to work on future versions of the Open Source AI Definition.
2. LF AI & Data Foundation’s “Model Openness Framework” (MOF)
In parallel, the Linux Foundation has an initiative of its own called LF AI & Data Foundation.2
In March 2024, LF AI & Data Foundation introduced the Model Openness Framework (MOF) with “17 critical components that constitute a truly complete model release”:

Unlike OSI’s top-level definition, MOF dives into the nitty-gritty building blocks.
MOF goes even further to define three levels (or “Classes”) of openness that a given AI model can achieve, depending on which of the above 17 components are available.
 3. Technical Report or Research Paper 4. Evaluation Results 5. Model Card 6. Data Card 7. Sample Model Outputs (Optional) Class II. Open Tooling 1. All Class III Components 2. Training, Validation, and Testing Code 3. Inference Code 4. Evaluation Code 5. Evaluation Data 6. Supporting Libraries & Tools Class I. Open Science 1. All Class II Components 2. Research Paper 3. Datasets 4. Data Preprocessing Code 5. Model Parameters (Intermediate Checkpoints) 6. Model Metadata (Optional) Table 1: Model Openness Framework Classes and Components")
From the accompanying paper:
Class III - Open Model: “Class III contains all the components required to study, modify, redistribute, and build upon a model without restrictions,
including for commercial and educational purposes.”
Class II - Open Tooling: “Class II provides model consumers the complete codebase including libraries and tools needed for training, assessing, and testing models themselves.”
Class I - Open Science: “Class I empowers the community to inspect models through the model lifecycle along multiple fronts, representing the gold standard for completeness and openness rooted in scientific principles.”
For visual learners:

LF AI & Data Foundation even released a handy Model Openness Tool (MOT) that helps evaluate individual models on the above dimensions.
That’s how we know that DeepSeek-R1 “only” qualifies for Class III, which still makes it an open model according to the MOF definition.

But while OSI and LF AI & Data keep working on robust definitions, we still don’t have an industry-wide standard or agreement.
Until we do, we’ll continue to see “open-source” labels by AI labs and dramatic Reddit fights.
Openness dimensions: A layman’s guide
I didn’t want to leave you with this less-than-satisfactory state of affairs.
I’m not a monster.
So I’ll go ahead and take a stab at highlighting some of the separate “moving parts” involved in evaluating how open a given AI model is.
As the MIT Technology Review article points out:
...depending on your goal, dabbling with an AI model could require access to the trained model, its training data, the code used to preprocess this data, the code governing the training process, the underlying architecture of the model, or a host of other, more subtle details.
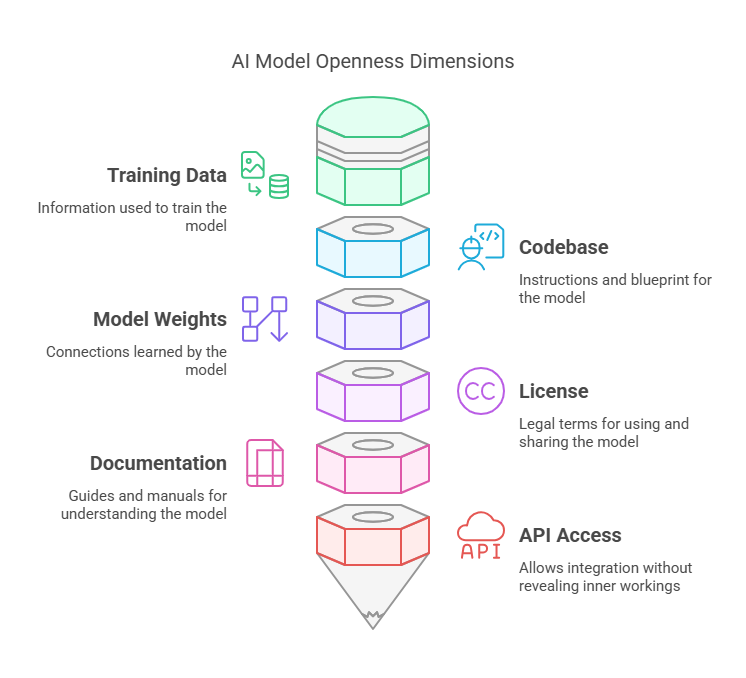
Here’s a cheat sheet for thinking about the different elements:
🗂️ 1. Training data
This is all the information “fed” to the model during training. For LLMs, this will typically be huge volumes of text scraped from the Internet. Ultimately, it’s how an LLM learns the relationship between words (or, more accurately, “tokens”).
Companies often don’t release their full training datasets, either out of privacy concerns, to safeguard proprietary data, or because, well…

🔣 2. Codebase
Think of the codebase as the blueprint or instructions for making the AI model. It typically includes the code used to train, run, and evaluate the model. If we think of the training data as the model’s “ingredients,” the codebase is the recipe that shows how to cook them.
Just as with training data, nominally “open” models may often choose to keep the codebase private.
⚖️ 3. Model weights
Everything the model learns during training is stored in the form of numerical interconnections known as “model weights.” These control how the model processes new inputs and generates outputs (text, images, etc.). Releasing these weights allows others to fine-tune the model for specific tasks, create new versions of it, and so on.
Today, the majority of so-called “open-source models” (including DeepSeek-R1) are more accurately described as “open-weight models,” because they don’t fully disclose the codebase or the training data.
🔓 4. License
This defines the legal terms for using, sharing, and modifying a model. Some, like the MIT license, are highly permissive and let others use the model for just about anything, including commercial projects. Others might restrict usage exclusively to research purposes.
A truly open model would have a permissive license that lets anyone use, modify, and share the model freely without significant limitations or preconditions.
📃 5. Documentation
A permissive license isn’t very useful if people can’t figure out how the model works. That’s where documentation, including the research paper, technical reports, model cards, etc. comes into play.
Think of documentation as a user manual for the model. Good documentation will explain how the model was built, how it works, and how to use or recreate it, making it another key indicator of how open a model is.
🔌6. API access
API access is technically not an openness dimension like the others.
It simply lets developers "plug" their applications into the model via an API (Application Programming Interface), without necessarily giving them any insight into the model’s inner workings. To wit: Even OpenAI provides API access to its otherwise closed, proprietary models.
While API access does nothing for transparency, it does let others build products or services around the model. This access isn’t always a given. For instance, Midjourney still doesn't offer official API access to its image model to this day.
To summarize:
Beyond the “open-source” label
Ultimately, what’s “open enough” will depend on your goal.
Building an app? Getting API access might be just fine. Want to fine-tune a model? You’ll need to at least know the weights.
As we’ve learned, when it comes to AI models, openness is a spectrum.
While the industry chases the perfect definition of "open-source AI," the rest of us will do well to take any openness claims by AI labs with a grain of salt, dig beyond the labels, and understand the different factors at play.
I hope I’ve helped you do just that.
🫵 Over to you…
If you were expecting perfect clarity, I’m sorry to disappoint.
But I hope this exploration gives you a better feel for the nuances involved in defining open-source AI.
What do you think of the above initiatives? Which approach makes the most sense? OSI, MOF, or perhaps a hybrid of the two?
If you have better insights into open-source definitions and want to point out any errors or omissions on my part, please let me know. I want to make sure the above overview is as accurate as possible.
Leave a comment or drop me a line at whytryai@substack.com.
More specifically, Llama’s limiting license and lack of access to e.g. training data.
So I guess the full name is “Linux Foundation AI & Data Foundation”? Foundationception!
OSI or MOF? Why not both^W neither? https://samjohnston.org/2024/11/24/openness-vs-completeness-data-dependencies-and-open-source-ai/
The original author of the Open Source Definition has views too: https://postopen.org/documents/real-open-source-ai
I kind of hate meta. Might be a bit irrational but, whatever. So, I've been suspicious of their open source high ground with llama. We're so open, ooooh lookit us, we're better. Now I kinda get it and I'm off to Reddit to watch the show