


Finally, a Beginner-Friendly ControlNet Demo!
ControlNet lets you "pose" AI subjects to better reflect your intended scenes. And now there's a free demo version that even a true beginner can use!

Happy Thursday, everyone!
Some of you may have already come across ControlNet, as it officially launched around February 11.
I know I did, and it looked pretty damn sweet!
But there was one issue: To use ControlNet, you’d have to either install Stable Diffusion locally or find a Google Colab.
Both of those require a bit of technical know-how. Since my Substack is aimed at complete beginners, that wouldn’t fly. It wouldn’t even walk, frankly.
But now there’s finally a demo out that lets even total noobs like us get a feel for what ControlNet is capable of.
Rejoice!
What is ControlNet?
ControlNet is the official implementation of this research paper on better ways to control diffusion models.
It’s basically an evolution of using starting images for Stable Diffusion and can create very precise “maps” for AI to use when generating its output.
So ControlNet can, say, take an iconic image like the Abbey Road cover:

Transform it into a “pose map” like this:
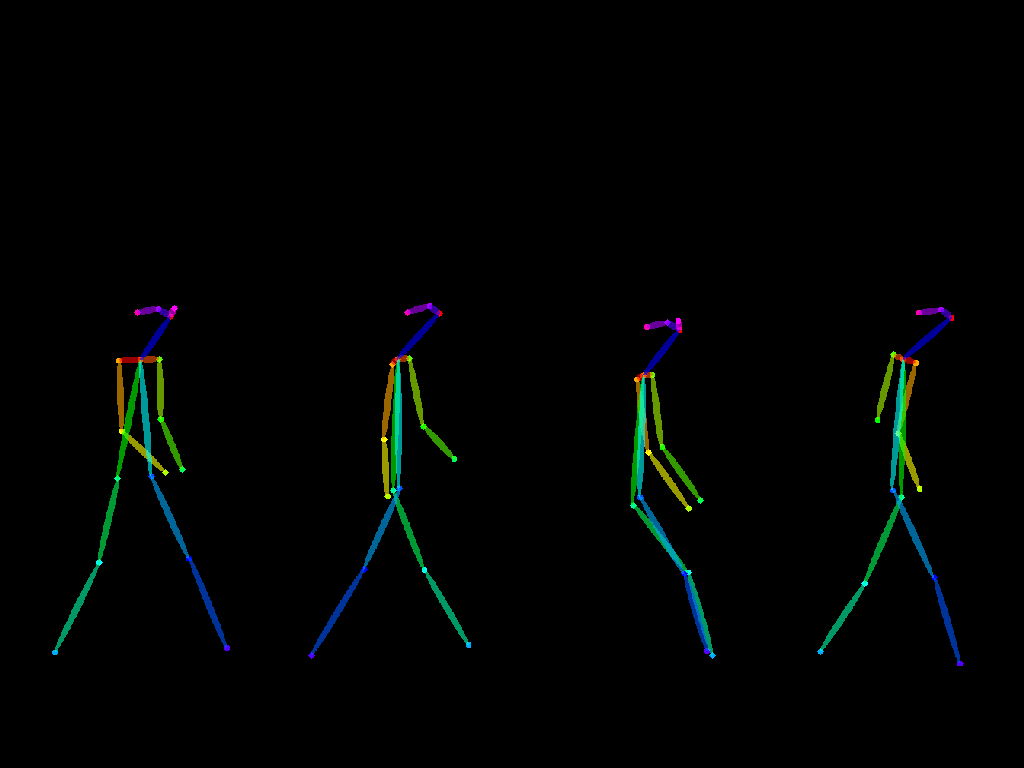
And then let me turn that into anything I could think of:



This video is a good look at how ControlNet works, and it also includes a tutorial for using the ControlNet Google Colab, if you’d like to give that a shot:
For the rest of us, there’s now a Hugging Face demo that makes ControlNet extremely accessible.
How to use the Hugging Face demo
It’s stupid simple.
You go to the Hugging Face demo page, then pick the tab for the type of map you’d like to generate:
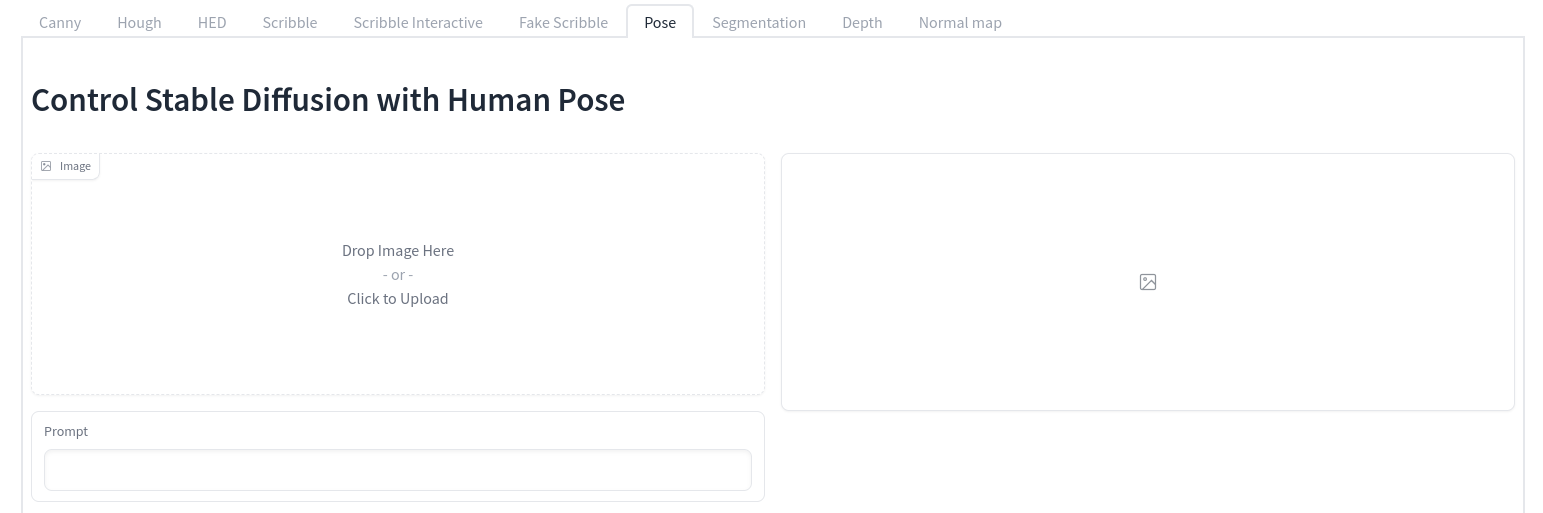
All the available models are really well described and illustrated in the ControlNet documentation. The two most straightforward ones are the “Scribble Interactive” and the “Pose” tabs.
The Scribble Interactive lets you directly feed ControlNet your crappy, crappy sketch:

Then demand something that doesn’t look like an affront to humanity:

The Pose tab is the one I used for the Abbey Road transformations above.
It lets you feed any photos of people (or even a movie scene) into ControlNet and use them as the benchmark for output images.
Once you get comfortable with the standard settings, there’s an “Advance Options” section for each tab that you can tweak to your liking.
Try to experiment with the different models to see what you like. The Hough Line Maps one is particularly good at wireframes for interior design:
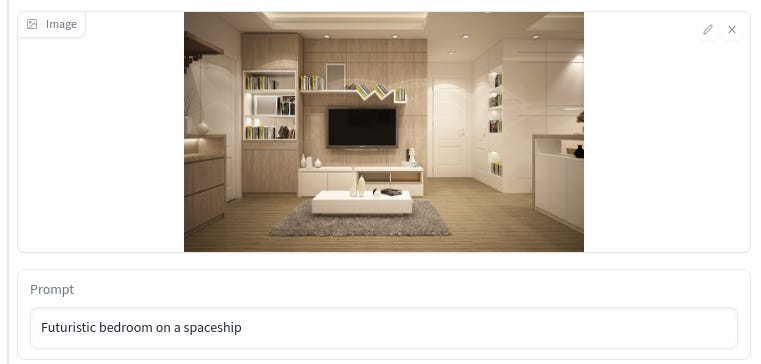


Now go out there and have fun, kids!
Two bonus posing tools
Still here?
Then let me share a couple of cool tools you might find handy. While you can always use any image (including your own photos) as a ControlNet reference, you might want even more control than that.
In that case, check out…
Posemaniacs: This is a free pose database for artists. Search through tons of ready-made poses, then zoom, pan, change viewing angle, etc. to find the right pose reference for your ControlNet image.
JustSketchMe: If you want complete control, this lets you create a scene with any number of characters and adjust their poses with micro-precision.
Over to you…
Have you already tried ControlNet? What have your impressions been? Do you use any other tools or methods to have more say in how your AI images turn out?
I’m always eager to learn more, so don’t hesitate to write me an email or drop a comment below.
“Why Try AI” is 100% free to read for everyone. There are no content paywalls or other pay-to-access features.
But you can help support my work through an optional paid subscription. It’s like buying me a fancy cup of coffee once a month. If you do, thank you!
I tried using a Posemaniac pose in the Hugging Face Control Net demo. It was pretty slow in my quick test, but it did work. Well, version 1 threw up an error, but version 1.1 did work.
Then I did the same thing in img to img on dezgo, and got pretty much the same thing, but faster.
Posemaniac seems quite useful, as that's a big improvement over searching google for a needed reference image.
Thanks for the link to Posemaniacs, that hits me right about where I am at the moment. I can see I'm going to be doing more img to img, this will certainly help.