


10X AI (Issue #45): Stable Audio 2.0, DALL-E 3 Image Editing, and Blue Hellhounds
Sunday Showdown #5: Runway vs. Pika: Who lip syncs better?

Happy Sunday, friends!
Welcome back to 10X AI: a weekly look at generative AI that covers the following:
AI news + AI fail (free): I highlight nine noteworthy news stories of the week and share a visual AI fail for your entertainment.
Sunday Showdown + AI tip (paid): I pit AI tools against each other in performing a specific real-world task and share a hands-on tip for working with AI.
So far, I had image models creating logos, AI song makers producing short jingles, AI-generated sound effects, and LLMs telling jokes.
Upgrading to paid gives you instant access to every Sunday Showdown + AI Tip and other bonus perks.
Let’s get to it.
This post might get cut off in some email clients. Click here to read it online.
🗞️ AI news
Here are this week’s AI developments.
1. Stable Audio 2.0 can play for 3 minutes
What’s up?
Stability AI just launched the sequel to the original Stable Audio.
Why should I care?
Stable Audio 1.0 was disappointing in my recent February test. Stable Audio 2.0 produces more coherent, higher-quality tracks and can generate up to 3 minutes of music from a single prompt. It also lets you condition a melody by humming or singing a tune. Finally, Stable Audio 2.0 was ethically trained on a licensed dataset from AudioSparx, “honoring opt-out requests and ensuring fair compensation for creators.”
Where can I learn more?
Read the official announcement post.
Try making tracks for free at StableAudio.com.
2. You can now edit DALL-E 3 images in ChatGPT
What’s up?
OpenAI introduced the option to edit specific areas of a DALL-E 3 image.
Why should I care?
Previously, it was impossible to make direct edits to anything DALL-E 3 generated within ChatGPT. You’d have to use third-party sites to change an image you liked. Now you can highlight areas to edit and request tweaks conversationally. It’s very similar to Midjourney’s Vary Region and other classic inpainting tools.
Where can I learn more?
Follow the official announcement thread on Twitter / X.
Read the detailed help article.
3. ChatGPT-3.5 no longer requires account creation
What’s up?
OpenAI made the original ChatGPT (GPT-3.5) accessible without signup.
Why should I care?
People who were previously hesitant to create accounts can now get a taste of ChatGPT without one. This should reduce friction and introduce the tool to a wider audience. Plus this change makes it convenient to ask quick one-off questions without first going through any sign-up or login steps.
Where can I learn more?
Read the official announcement post.
Start using ChatGPT-3.5 at chat.openai.com.
4. KREA’s “HD” model can remix up to three styles
What’s up?
KREA AI now has an “HD” model for paid users that can be conditioned on up to three images.
Why should I care?
Being able to use input images as a style reference gives you greater control over the exact look of your final picture. (Midjourney introduced a style reference feature two months ago.) KREA’s version lets you remix styles from up to three separate reference images and play with their weights in real time.
Where can I learn more?
Check out the official announcement thread on Twitter / X.
Try it for yourself at krea.ai (you’ll need at least a “Basic” paid plan)
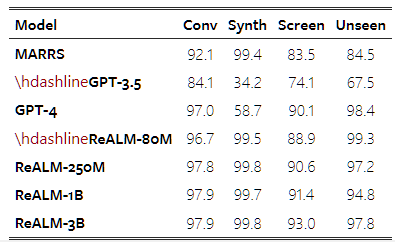
5. Apple’s ReALM models rival GPT-4
What’s up?
Apple researchers unveiled an approach that improves an LLM’s ability to understand what the user is referring to in a given context.
Why should I care?
By improving “reference resolution,” Apple was able to substantially improve an LLM’s performance on on-screen tasks and more. Apple’s smallest model (ReALM-80M) is comparable to GPT-4 while the largest model (ReALM-3B) outperforms it. Apple is expected to use this method to make its Siri and similar assistants a lot better.
Where can I learn more?
Read the research paper.
Read this article by Apple Insider.
6. Claude can now interact with external tools
What’s up?
Anthropic announced that Claude (via API) can now interact with external tools using structured outputs.
Why should I care?
OpenAI introduced “function calling” in its GPT models in June 2023. Now, Claude can do the same and complete additional tasks that rely on third-party sites. This enables developers to build more complex and granular applications where Claud interacts with multiple tools. (The Claude chatbot on claude.ai doesn’t have this ability yet.)
Where can I learn more?
Check out the announcement thread on Twitter / X.
Consult Anthropic’s “tool use” guide.
7. Command R+ is a business-oriented LLM

What’s up?
Cohere launched a state-of-the-art LLM designed for enterprise use called Command R+.
Why should I care?
Command R+ is purpose-built to handle business workloads and offers best-in-class performance on multilingual tasks in 10 languages, tool use, and advanced RAG to reduce hallucinations. It goes head-to-head with GPT-4 Turbo while being significantly cheaper to run.
Where can I learn more?
Learn more in Cohere’s help article.
8. OpenAI’s Voice Engine clones voices in 15 seconds
What’s up?
OpenAI teased a “small-scale preview” of its Voice Engine model which the company apparently used internally since late 2022.
Why should I care?
Voice Engine is scary good at replicating a person’s voice from only 15 seconds of input. Because of this, OpenAI isn’t releasing the model broadly at this time, working instead with select partners to understand the risks. The company has also highlighted a number of steps to prepare society for the rise in realistic synthetic voices.
Where can I learn more?
Read the official post (and hear voice cloning examples).
9. VoiceCraft does the same and is already out

What’s up?
Researchers at the University of Texas at Austin have open-sourced VoiceCraft, which can replicate voices from just a few seconds of input.
Why should I care?
While OpenAI is holding back for fear of real-world impact, VoiceCraft is freely available for download. It can convincingly replicate voices from just several seconds of input and allows you to adjust audio clips by editing the transcript. This field is moving fast and we should probably be extra skeptical about voice-based evidence going forward.
Where can I learn more?
Visit the project page with many voice examples.
Read the research paper (PDF).
Get the model at GitHub.
🤦♂️ 10. AI fail of the week
Not all giant blue dogs go to heaven. Right, Adobe Firefly?

Anything to share?
Sadly, Substack doesn’t allow free subscribers to comment on posts with paid sections, but I am always open to your feedback. You can message me here:
⚔️ Sunday Showdown (Issue #5) - Runway vs. Pika Labs: Which one is best at lip-syncing?
In March, both Pika Labs and Runway launched lip-syncing features that can make characters in your videos say stuff.
So naturally, I wanted to see how they compared.
Today, I’ll be making two characters talk using both Pika and Runway.
Here’s a teaser for free subscribers:
Let’s go!